The Stanford OVAL
Knowledge Assistant
We build LLM-Augmented Cognition Systems (LLM-CSys) that combine the expressive language skills of LLMs with the interpretability and reliability of software systems. We connect LLMs with databases, compilers, and executive functions to create assistants that are more trustworthy and helpful.




ABOUT OUR WORK
 Standalone LLMs are like the speech centers in our brains. They
rely on the prefrontal cortex for executive functions (attention, long-term planning) to communicate effectively.
Standalone LLMs are like the speech centers in our brains. They
rely on the prefrontal cortex for executive functions (attention, long-term planning) to communicate effectively. 
- Professor Monica Lam
RECENT TALK

"Controlling and Grounding Large Language Models for Conversational Assistants"
Generative AI and Foundation Models Workshop, Stanford Computer Forum, April 12, 2023
We invite students, researchers, and corporations to join us to advance the state of the art in conversational agents research and to apply the technology to real-world use cases.
News
November 2024 — Shicheng Liu and Sina Semnani presented the paper SPINACH: SPARQL-Based Information Navigation for Challenging Real-World Questions at the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), Miami, Florida, USA.
November 2024 — Yucheng Jiang presented the paper Into the Unknown Unknowns: Engaged Human Learning through Participation in Language Model Agent Conversations at the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), Miami, Florida, USA.
November 2024 — Kazuaki Furumai presented the paper Zero-shot Persuasive Chatbots with LLM-Generated Strategies and Information Retrieval at the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), Miami, Florida, USA.
August 2024 — Jialiang Xu presented the paper SPAGHETTI: Open-Domain Question Answering from Heterogeneous Data Sources with Retrieval and Semantic Parsing at the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), Bangkok, Thailand.
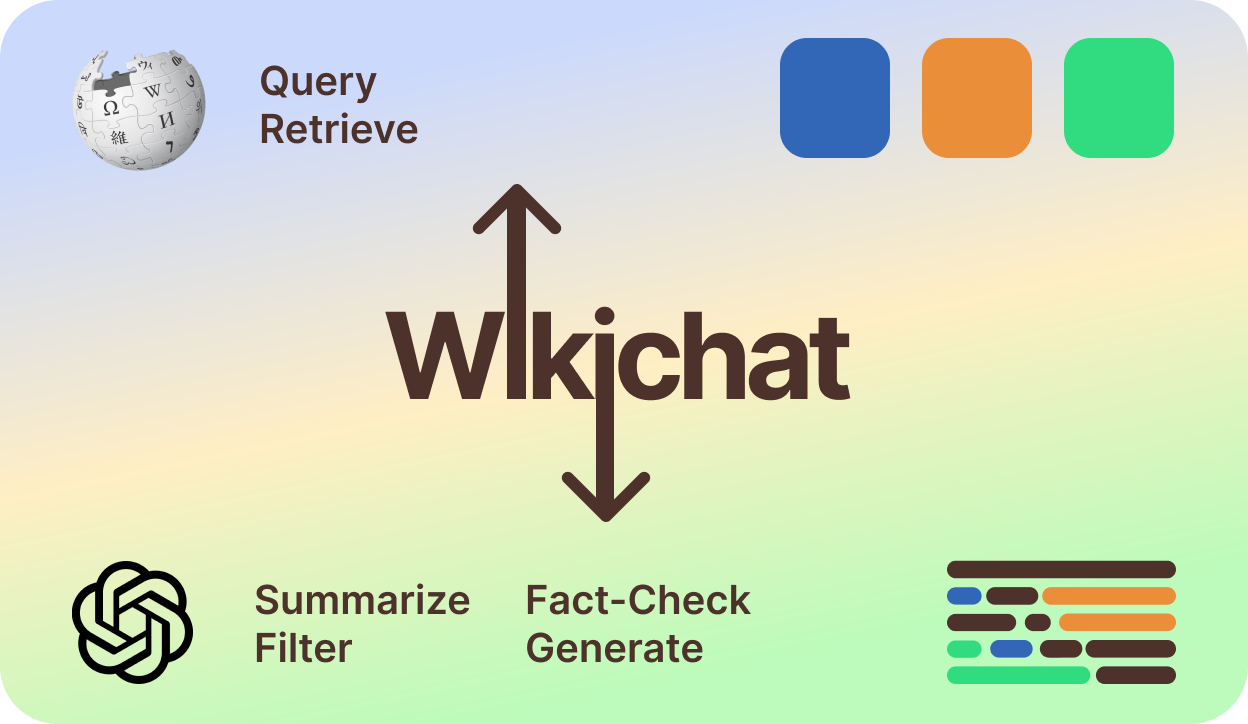
June 2024 — WikiChat: Stopping the hallucination of large language model chatbots by few-shot grounding on Wikipedia won The Wikimedia Foundation Research Award of the Year 2024!
June 2024 — Yijia Shao presented the paper Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models at the 2024 North American Chapter of Association for Computational Linguistics (NAACL), Mexico City, Mexico.
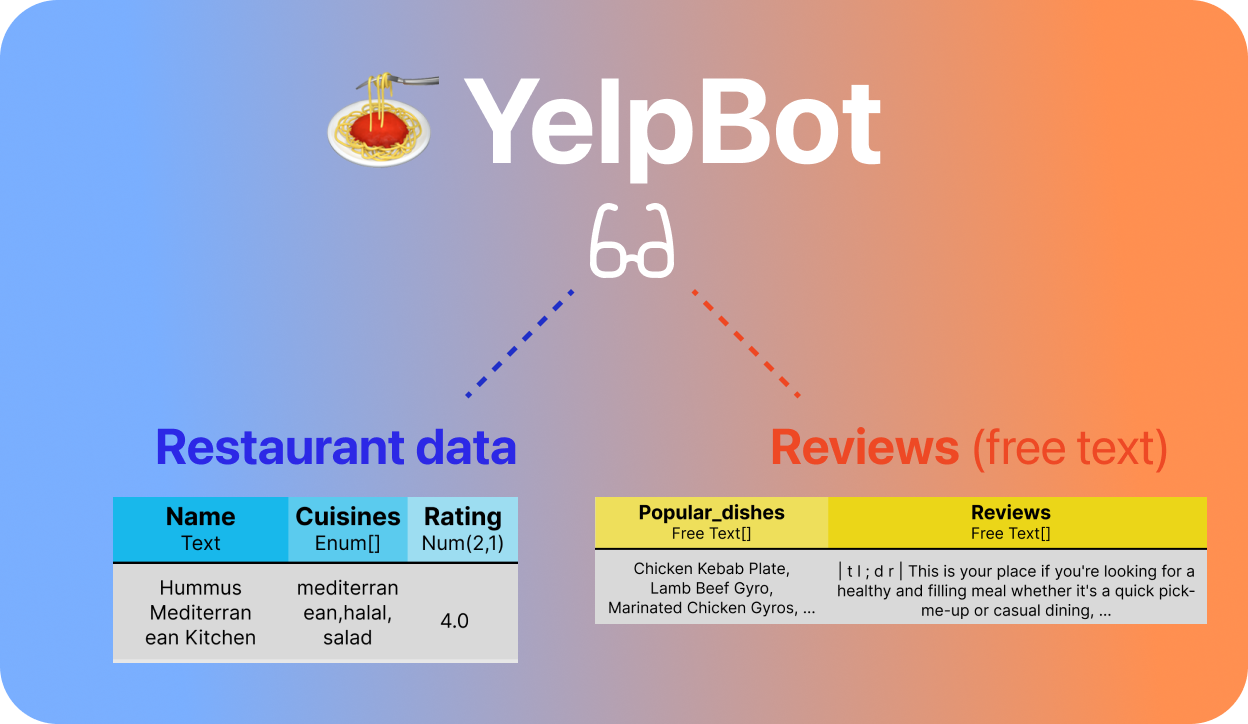
June 2024 — Shicheng Liu presented the paper SUQL: Conversational Search over Structured and Unstructured Data with Large Language Models at the 2024 North American Chapter of Association for Computational Linguistics (NAACL), Mexico City, Mexico.
May 2024 — 3 OVAL projects are awarded 2024-2025 Magic Grants! "African History from the Bottom Up with LLM-Augmented Agents" led by Sina Semnani, "Cross-Lingual Multi-Perspective News" led by Jialiang Xu, and "DataTalk: All Documents and Data, All at Once, All Verified" led by Shicheng Liu.
Mar 2024 — Jackie Yang presented the paper AMMA: Adaptive Multimodal Assistants Through Automated State Tracking and User Model-Directed Guidance Planning at the 2024 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Orlando, FL.
Dec 2023 — Elizaveta Pertseva presented the paper Fine-tuned LLMs Know More, Hallucinate Less with Few-Shot Sequence-to-Sequence Semantic Parsing over Wikidata at the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), Singapore.
Dec 2023 — Sina Semnani presented the paper WikiChat: Stopping the Hallucination of Large Language Model Chatbots by Few-Shot Grounding on Wikipedia at the Findings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), Singapore.
July 2023 — Mehrad Moradshahi presented the paper X-RiSAWOZ: High-Quality End-to-End Multilingual Dialogue Datasets and Few-shot Agents at the Association for Computational Linguistics (ACL), Toronto, Canada.
May 2023 — Monica Lam presented a plenary talk "Controlling and Grounding Large Language Models for Conversational Assistants" at the Xpo Research Symposium of the Institute for Computational and Mathematical Engineering.
May 2023 — Mehrad Moradshahi presented two papers Zero and Few-Shot Localization of Task-Oriented Dialogue Agents with a Distilled Representation and Contextual Semantic Parsing for Multilingual Task-Oriented Dialogues at the European Chapter of the Association for Computational Linguistics (EACL), Dubrovnik, Croatia.
April 2023 — Monica Lam presented "Controlling and Grounding Large Language Models for Conversational Assistants" at the Generative AI and Foundation Models Workshop in the Computer Science Annual Affiliates Meeting.
Nov 2022 — Monica Lam presented a keynote at the 9th International Conference on Information Management and Big Data (SIMBig) in Lima, Peru.
Nov 2022 — Monica Lam presented a keynote on "Taming Neural Language Models into Trustworthy Conversational Virtual Assistants" at the Open Data Science Conference in San Francisco.
Acknowledgement
OVAL acknowledges the support of the National Science Foundation, the Alfred P. Sloan Foundation, the Verdant Foundation, Microsoft Azure Cloud Credits, KDDI, Sony Playstation, JP Morgan Chase Faculty Research Award, HAI Seed Grants, Linux Foundation, and the Open Voice Network. We also want to thank our partners Alpha Vantage, Baidu, Picovoice, Yelp, and You.com for their support.